One of the most heard mantras among digital marketing professionals and that you will have heard sick of is that SEO takes time. We can say that it is the modern version of the motto “Rome was not built in a day”.
Therefore, one of the biggest challenges we have in our SEO Positioning Agency when we start a new project, is to find the key that allows us to launch a client’s domain in the SERPs in a short time. Precisely, this is the case that we will see today.
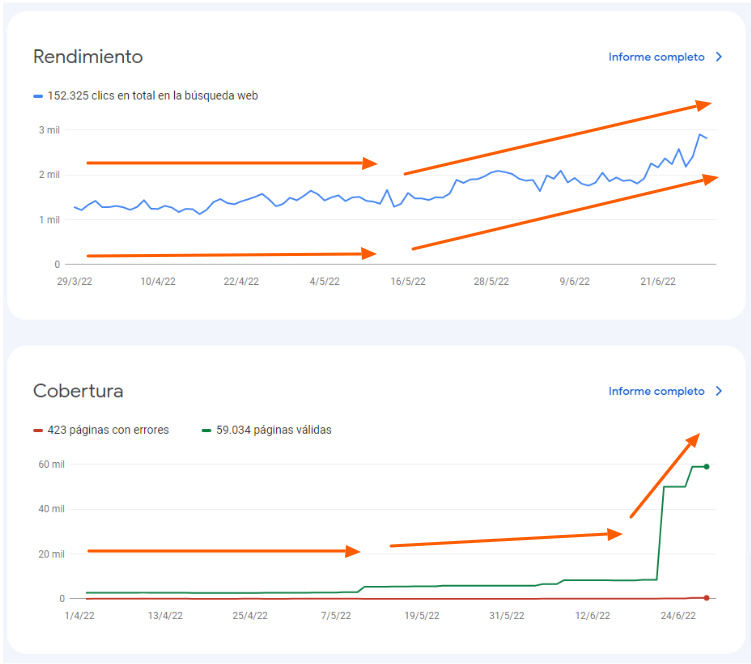
In the SEO Indexing Success Story we will see how we have helped a German classifieds website with multi-country ambitions take off in just 6 weeks (21 days if we remove the audit time), which we have helped after more than 12 months of stagnation. (GSC > Performance) – Period from March 29, 2022 to June 28, 2022
In just 21 days, we have achieved the following results:
∆ 92% of organic visits going from 1,513 to 2,907 daily clicks.
∆ 85.76% of impressions on Google going from 14,780 results shown to 27,308 appearances in the SERPs.
And all this, thanks to the fact that in just over 21 days, we have achieved the following results:
Days after the SEO audit we have increased the indexation of the project from 8k URLs to almost 60k. Which explains the increase in impressions and clicks.
Starting point: A project stalled since June 2021
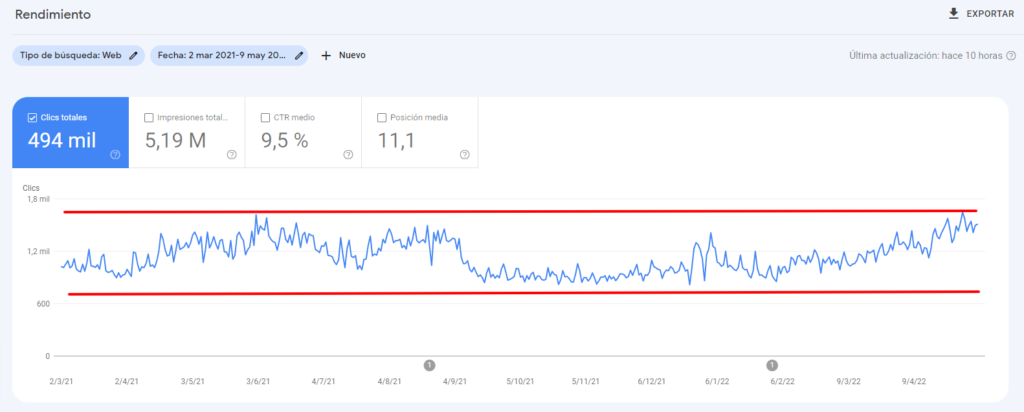
To better understand what has been achieved, it is necessary to describe the context of the state of the project before our intervention. We started from a domain that had suffered a significant drop in organic traffic that the property managed to stabilize. However, in the last 12 months there was a total lack of progress.
(GSC > Performance) – Period from March 2, 2021 to May 9, 2022
Daily organic traffic in this period was stagnant in a range ranging from 820 to 1,623 daily visits. This was insufficient for our client. In addition, in these cases, there is a high risk of a relapse. You already know that in SEO there are rarely flat trends. Either it goes up or it goes down.
And the fact is that, generally, the situation stabilizes after making some arrangements, but the underlying problem is rarely 100% resolved, so Google sooner or later stops showing the page in the top positions of its results.
The Challenge: How to open crawling for thousands of URLs without opening the SEO Pandora’s box
Fortunately, the SEO audit of the domain revealed that there were crawling and indexing problems:
On the one hand, through robots.txt, the search engines were being prevented from crawling the versions in other languages of the website.
At the same time, thecardscreated by users on the website were not being indexed correctly.
A bad configuration of the category pages linking to parameterized versions of the cards that in turn pointed to the original version through a rel=”canonical”, was preventing the indexing of that content by the search engines. Leaving a large number of URLs with SEO value without the possibility of positioning.
In addition, the configuration of the web pagination was deficient. Only the main page of the category was indexed and the rest of the pages were kept with a noindex directive.
These three points:
Category pagination not optimized.
Cards not indexed.
Version of the website in other languages blocked.
They were causing thousands of URLs to remain uncrawled and unindexed. Preventing the project from taking off.
The question: Will we have enough crawl budget to uncover the entire domain?
It was clear that the project needed to achieve the indexation of all URLs with positioning value. But, if you’ve been in the SEO world for a while, you know that an unclogging operation for a high volume of URLs is not without risks.
To make ourselves understood:
Opening the crawl in a project of this size is like opening a bottle of champagne just taken out of the drum of a washing machine centrifuging at 1,800 RPM.
When you do it, you’re going to skyrocket, but right after that you’ll fall, losing most of the traffic you’ve gained.
And that’s because, when you open the crawler, you’re going to be the first to lose the most traffic you’ve gained.
Co-CEO and Head of SEO at iSocialWeb, an agency specializing in SEO, SEM and CRO that manages more than +350M organic visits per year and with a 100% decentralized infrastructure.
In addition to the company Virality Media, a company with its own projects with more than 150 million active monthly visits spread across different sectors and industries.
Systems Engineer by training and SEO by vocation. Tireless learner, fan of AI and dreamer of prompts.